SQL Syntax
Here is the syntax for the SQL SELECT statement that the SQL parser recognizes.
About SQL Syntax
- SQL syntax is case insensitive.
- Field and table names are case sensitive
- Legend
-
- [ x ] - Optional (one or none)
- [, x ... ] - Optional additional values, in a comma-separated list
- x | y - Choose one. Curly braces are added when needed: { x | y } ...
- CAPITALIZED - SQL Keyword (case insensitive)
- italicized - Value you supply. (Table names and column names are case-sensitive)

Note:
When you make a SQL query, you are not querying the platform database directly. Rather, you are querying a view of the database that is restricted by your role permissions, so the records and fields you can see using SQL are the same as those you see when using the GUI. In addition, the platform implements various safeguards to prevent SQL Injection attacks.
- Considerations
-
- SQL syntax is not case-sensitive, except for table names and field names.
- Backticks are (`) are needed around any table or field name that is one of the SQL Reserved Words.
- For example: SELECT * FROM `Order`
- Without the backticks, you get an error like this:
- Encountered "Order" at line column 15. Was expecting one of (...
- That error means the parser found a word it recognized, but didn't find other things it expected before it got to that word.
- When either a table name or a field name is reserved word, and both are used together, then backticks are needed around the combination.
- For example: `Order.order_number`
- If you do a query on different tables that have fields with the same name, you should provide column aliases for those fields. (Otherwise, a query for A.phone and B.phone identifies both sets of values as "phone". A column alias like A.phone AS A-phone makes it possible to tell which table a set of values came from.)
- Learn more: column_expr
- Learn more:
SELECT Statement
In a select statement, you designate one or more columns separated by commas (or "*" for all columns), plus a table or join to get the data from, and additional options:
- Examples
- <syntaxhighlight lang="sql" enclose="div">
SELECT * FROM Customers SELECT * FROM Customers LIMIT 80 SELECT * FROM Customers ORDER BY zip_code, customer_name </syntaxhighlight>
- Syntax
- SELECT
- [DISTINCT]
- [(] column_expr [, column_expr ...] [)]
- FROM [(] table [, table ...] [)]
- [WHERE where_clause]
- [GROUP BY col_name [, col_name ...]
- [WITH ROLLUP]
- [HAVING where_clause]
- ]
- [ORDER BY col_name [ASC|DESC] [, col_name [ASC|DESC] ...]
- [LIMIT {maximum_rows | offset, maximum_rows} ]
-
Note: Group by col_name does not support ASC and DESC in MySQL 8
where:
- DISTINCT
- Eliminates duplicate rows from the result set.
- For example: DISTINCT(customer_name, address)
- (Parentheses are optional, but must be matched if present.)
- WITH ROLLUP
- Adds summary rows that aggregate values for each group.
- HAVING
- Is only allowed as part of GROUP BY, for performance reasons. (WHERE does the same thing outside of a GROUP BY clause, only more efficiently.)
- ASC
- Ascending (the default).
- DESC
- Descending.
- maximum_rows
- Maximum number of rows to return.
- offset
- The row to start from. Offset for the first row is zero (0).
- Learn more:
column_expr
- * | table_alias.* | col_name [ [AS] col_alias ] | expr [AS] col_alias
where:
- col_alias
- Used for the column name in the result set in the SQL Browser, or for the tag name in the REST execSQL resource.
- Required when an expression is specified.
- Can be used as a field name in a group_by_clause or order_by_clause.
- For example:
- SELECT CONCAT(last_name,', ',first_name) AS full_name
- FROM Customer_Contacts ORDER BY full_name;
- SELECT CONCAT(last_name,', ',first_name) AS full_name
table
- Example
- <syntaxhighlight lang="sql" enclose="div">
SELECT cust.customer_name, orders.order_amount
FROM `Order` as orders, Customer AS cust GROUP BY cust.customer_name WITH ROLLUP
</syntaxhighlight>
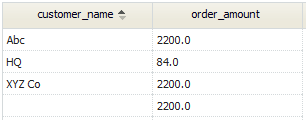

- Note: The "Order" table must be enclosed in backticks, because that name is a reserved word in SQL. (If used to qualify a field name, the syntax would be: `Order.fieldName`.)
- Syntax
- table_name [ [AS] table_alias ]
- | join_table
join_table
- Learn more: About Table Joins
on_clause
- on_condition [ {AND|OR} on_condition ...]
on_condition
- table_alias.col_name IS [NOT] NULL
- | table_alias.col_name = table_alias.col_name
- | table_alias.col_name != table_alias.col_name
- | ( on_clause )
- Considerations
- If multiple tables are specified, a JOIN is implied
- An INNER join (aka a STRAIGHT join) is the default.
- table_alias is required when specifying columns in a JOIN.
where_clause
An expression that evaluates to true or false for a row. When true, the row is selected.
- Example
- <syntaxhighlight lang="sql" enclose="div">
SELECT orders.order_number, Item.amount
FROM `Order` as orders, OrderItems AS Item WHERE Item.related_to_Orders = orders.id ORDER BY orders.order_number
</syntaxhighlight>
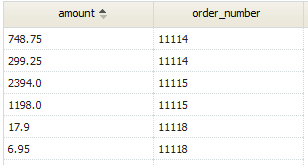

- Syntax
condition
expr
string
A sequence of alphanumeric characters and/or symbols, enclosed in single quotes:
- 'a string'
Strings can also "escape sequences" for characters that do not appear on the keyboard:
Escape
SequenceCharacter \0 ASCII NUL (0x00). \' Single quote ("'"). \" Double quote ("""). \b Backspace character. \n Newline (linefeed). \r Carriage return. \t Tab character. \\ Backslash ("\"). \% The "%" character. Used in a [NOT] LIKE expression, so the character isn't interpreted as a wildcard. \_ The "_" character. Used in a [NOT] LIKE expression, so the character isn't interpreted as a wildcard. \Z ASCII 26 (Control+Z). To prevent the character from being interpreted as End-of-File in Windows. wildcard_string
A string containing one or more wildcards, used in a [NOT] LIKE expression:
xx yy % Matches any number of characters, or zero characters. _ Matches exactly one character. pattern_string
A string containing a regular expression, used in a [NOT] REGEXP expression:
Character(s) Meaning . Any character, including newlines. * Zero or more of previous character. As in: '.*' + One or more of previous character. As in: 't+' ? Zero or one of previous character. As in: 'T?' | XYZ' (...) XYZ) Company', '(ABC|XYZ)( Company)?'
(The latter pattern matches "ABC", "XYC", "ABC Company", and "XYZ Company".)[...] Character set:
- [abcdef] - match any of the characters in the set
- [a-f] - match any of the characters in the range
- [a-fA-FzZ] - Combination, Match any of the specified characters,or any of the characters in either range.
- [^...] - Negation. Match anything other than the characters specified in the set.
^ Beginning of a string when it is in a pattern.
"Not", when it is the first character in a character set.
$ End of string. Note:
Since strings use backslash escape syntax (for example, "\n" to represent the newline character), you must double any backslash characters you use in your REGEXP strings. For example, to include a question mark (?) in a string, the pattern matcher needs to see \?. (So it looks for a question mark character, instead of interpreting the question mark as "zero or one".) To get that string to the pattern matcher, you specify \\?. String processing reduces the \\ to \, so the regular expression processor sees \?, as intended.For example, this expression evaluates as true:
- SELECT 'Question?' REGEXP 'Q.*\\?'
number
Numbers can be specified as integers:
- 1221
- 0
- -32
Or as floating point/decimal numbers:
- 294.42
- -32032.6809e+10
- 148.00
date/time
- Learn more: SQL Date and Time Functions
Date "As Entered" Date/Time "Convert to Local" Date/Time SQL Browser 'YYYY-MM-DD'
(UTC Format)'YYYY-MM-DD hh:mm:ss' 'YYYY-MM-DDThh:mm:ssZ'
(UTC Format)REST 'YYYY-MM-DD'
(UTC Format)'YYYY-MM-DD hh:mm:ss' 'YYYY-MM-DDThh:mm:ssZ'
(UTC Format)Java User format, specified
in Company InformationUser format, in user timezone User format, in user timezone