About Table Joins
In a SQL query, you can join multiple tables together. In effect, you make one large virtual table to SELECT rows from.
How a Join Works
Whenever you specify multiple tables in a SQL query, a join is implied. If you don't specify any other selection criteria, the result is the cartesian product of the rows in the individual tables. So if table Alpha has rows A and B, while table Beta has rows 1 and 2, then the query:
- SELECT * FROM alpha,beta
returns 4 rows:
- A + 1
- A + 2
- B + 1
- B + 2
In general then, a table join will return N*M rows, where N & M are the number of rows in each table, respectively.
Of course, you're rarely interested in all possible combinations of all rows. What you're really interested in are the rows where one of the columns in table Alpha matches one of the columns in table Beta. And in general, the matching data you're looking for will be specified by a Lookup relationship.
To make it more concrete, consider the Sample Order Processing System:
- The Orders object has a Lookup to Customers
- That relationship is created by a field in the Orders object, related_to_Customer that contains the record ID of a Customer record.
- A SQL Join returns the product of all records in both tables:
- Order 1 for Customer A + Customer A
- Order 1 for Customer A + Customer B
- Order 1 for Customer A + Customer C
- Order 2 for Customer A + Customer A
- Order 2 for Customer A + Customer B
- Order 2 for Customer A + Customer C
- ...
- Order 1 for Customer B + Customer A
- Order 1 for Customer B + Customer B
- Order 1 for Customer B + Customer C
- etc.
- The records we're going to care about (highlighted above) are the ones where the related_to_Customer field in the Orders record matches the record ID of a Customer record.
- That relationship is Order.related_to_customer = Customer.id
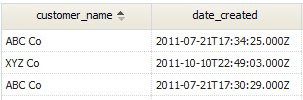
The only remaining refinement to that concept is that, when specifying multiple tables in a SQL query, table aliases are required, and you use those alias to specify fields. So a full query can look something like this:
<syntaxhighlight lang="sql" enclose="div"> SELECT c.customer_name, o.date_created
FROM Customer AS c, `Order` AS o WHERE o.related_to_Customer = c.id
</syntaxhighlight>

- Note:
The table named "Order" needs to be enclosed in backticks, because "ORDER" is a reserved word in SQL. So it is specified as: `Order`. (If used for a field name directly, the syntax would be: `Order.fieldName`.)
INNER JOIN
An INNER Join is the default join. It returns only those rows that match the condition specified in an ON clause. So these two queries produce the same results as the previous example:
<syntaxhighlight lang="sql" enclose="div"> SELECT c.customer_name, o.date_created
FROM Customer AS c INNER JOIN `Order` AS o ON o.related_to_Customer = c.id
SELECT c.customer_name, o.date_created
FROM Customer AS c JOIN `Order` AS o ON o.related_to_Customer = c.id
</syntaxhighlight>
Here, the row-matching criteria is specified in the ON clause. (When the tables are in a comma separated list, the WHERE clause works, but when JOIN is specifed, the ON clause is required.)
LEFT and RIGHT Joins
Sometimes you want to include rows that don't have a matching value. To do that, you use a LEFT or RIGHT join.
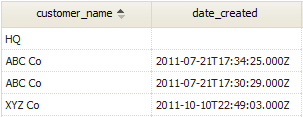
For example, suppose you want a list of customers and the orders they made last month. A simple query like the one shown above tells you which customers made orders, but it doesn't tell you which ones didn't make an order. Of course, you could issue a separate query to get that information, but you can also get all of the information in a single list, by issuing a LEFT or RIGHT join.
So for a query of Customers AS c, Orders AS o:
- A LEFT join includes all rows in the Customers table (the table on the left) that don't have a matching row on the right.
- A RIGHT join includes all rows in the Orders table (the table on the right) that don't have a matching row on the left.
For example:
<syntaxhighlight lang="sql" enclose="div"> SELECT c.customer_name, o.date_created
FROM Customer AS c LEFT JOIN `Order` AS o ON o.related_to_Customer = c.id
</syntaxhighlight>

Nested Joins
A nested join is one that is placed in parentheses, to make it evaluate first. A nested join is necessary when:
- You have three tables, A, B, and C.
- You want to join all three tables together (A join B join C) in such a way that the following rules hold true:
- You want to get ALL records in table A.
- You want to get all records in table B that correspond to table A,
but ONLY IF there is also a record in table C that corresponds to table B.
- (This [post] by Ben Nadel has a great analysis of why a nested join is the only way to satisfy those requirements.)
To illustrate the concept, consider the following tables: Customers, CustomerContacts, and EmailAddresses, where:
- Each contact is associated with a single customer
- Each email address is associated with a single contact,
and a contact can have multiple email addresses.
We want to select all Customer records, and all related contacts, but only if those contacts have a related email address.
To do that, we use a nested join:
- We use parentheses to group the CustomerContacts/EmailAddresses join, so it is executed first.
- We do an INNER join on those tables, so the intersection is selected, giving us only customer contacts that have email addresses.
- Then those rows are joined with Customers to give us the results we want.
Here is the code:
<syntaxhighlight lang="sql" enclose="div"> SELECT
c.customer_name, cc.contact_name, e.addr AS contact_email
FROM
Customer c
LEFT JOIN (
CustomerContacts AS cc INNER JOIN EmailAddresses AS e ON cc.id = e.related_to_customercontact) ON
c.id = cc.related_to_Customers
</syntaxhighlight>
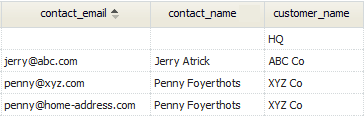

In this case, Carrie Atune (another contact at ABC Co) is not listed, because she has no email address. And even though the HQ company has no contacts listed at all, it still appears in the result set, sorted to the top because its data-field values are null.